
Mit paperless-gpt wurde ein hilfreiches Tool entwickelt, welche Dokumente aus Paperless-ngx ausliest und die Metadaten verbessert: Bessere Tag-Zuweisung, Erstellung eines sinnvollen Titels, KI-basiertes OCR und vieles mehr. In diesem Beitrag erkläre ich, wie paperless-gpt per Docker installiert, eingerichtet und mit einem lokalen KI-Modell verwendet wird. Voraussetzung ist, dass eine Paperless-ngx-Instanz bereits existiert.
Beachte, dass KI sehr rechenintensiv ist und daher gute Hardware benötigt. 8 GB RAM, eine starke GPU und CPU sind hier mindestens erforderlich. Die Einrichtung auf meinem Synology DS920+ NAS mit 8GB RAM war nicht möglich, da selbst hier die Leistung viel zu schwach war.
Paperless-ngx mithilfe von Docker unter Debian installieren
Paperless-gpt greift per API auf deine Paperless-ngx-Instanz zu. Begib dich dazu zunächst in Paperless-ngx, klicken oben rechts auf deinen Namen und wähle Mein Profil aus. Hier findest du deinen API-Authentifizierungstoken. Speichere diesen zwischen. Er wird gleich benötigt.
Auf GitHub findest du die docker-compose Datei: https://github.com/icereed/paperless-gpt?tab=readme-ov-file#docker-compose
In der Config sind einige Änderung notwendig. Die notwendigsten hier erklärt:
- PAPERLESS_BASE_URL: Trage hier die IP-Adresse der Paperless-ngx-Instanz ein
- PAPERLESS_API_TOKEN: Trage hier deinen API-Key ein
- Entferne die Kommentare im Bereich "# Option 4: Ollama (Local)", um ein lokales Modell zu verwenden
- OLLAMA_HOST: Wird zu "http://ollama:11434"
- OLLAMA_CONTEXT_LENGTH: Je nach Leistung, worauf paperless-gpt läuft, kannst du hier einen höheren oder niedrigeren Wert festlegen
- TOKEN_LIMIT: Je nach Leistung, worauf paperless-gpt läuft, kannst du hier einen höheren oder niedrigeren Wert festlegen. Desto höher, desto bessere Ergebnisse
- LLM_LANGUAGE: Verwende den Wert "German", damit die KI Dokumente auf Deutsch untersucht und bearbeitet
- OCR_PROVIDER: Wert "llm"
- VISION_LLM_PROVIDER: Trage "ollama" für ein lokales KI-Modell ein
- VISION_LLM_MODEL: "minicpm-v" für Ollama
- OCR_LIMIT_PAGES: Sollen alle Seiten eines Dokuments per OCR gelesen werden, verwende den Wert "0"
Passe ggf. noch die Volumes-Pfade an. Außerdem werden folgende zwei Zeilen entfernt, da paperless-gpt in dieser Konfiguration unabhängig von paperless-ngx läuft:
depends_on:
- paperless-ngx
Dafür wird am Ende noch folgendes eingebunden, damit Ollama als Container läuft:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: no
ports:
- "11434:11434"
volumes:
- ./ollama:/root/.ollama
environment:
- OLLAMA_NUM_PARALLEL=1
Nun können die beiden Container einmal gestartet werden:
docker-compose up -d
Installiere für die Dokumenten-Analyse sowie das KI-basierte OCR noch folgenden beiden Modelle "minicpm-v" und "qwen3:8b":
docker exec -it ollama ollama pull minicpm-v
docker exec -it ollama ollama pull qwen3:8b
Im Browser erreichst du paperless-gpt jetzt über folgende Adresse: http://localhost:8080
Im empfehle zunächst die Prompts für die jeweiligen Aktionen durchzugehen. Dazu begibt man sich zum Reiter Settings. Hier legst du die Bedingungen und Anweisungen fest.
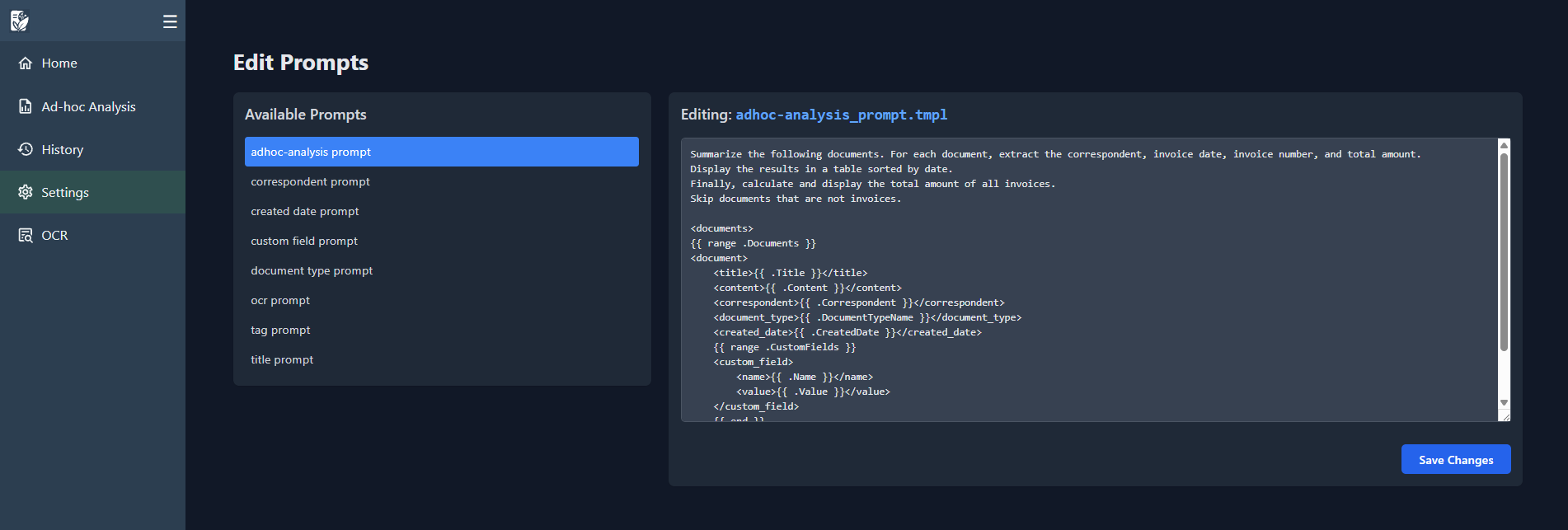
Wenn du Änderungen vorgenommen hast, musst du den Container einmal komplett herunterfahren und neu erstellen, damit der Cache geleert wird:
docker-compose down
docker-compose up -d --force-recreate
Paperless-gpt zeigt dir unter Home noch keine Dokumente an, da lediglich Dokumente eingelesen werden, die den Tag paperless-gpt haben. Nun heißt es also, den Dokumenten, die man überarbeiten möchte, diesen Tag zu vergeben. Sobald das geschehen ist, werden die Dokumente aufgelistet. Hier kannst du per Klick auf Generate Suggestions direkt Vorschläge generieren und bei Bedarf per Klick auf das Dokument anwenden.
Im Bereich OCR kannst du eine Dokumenten-ID angeben (diese findest du in der Paperless-ngx URL des Dokuments: http://localhost/documents/XXX/details), um ein Dokument per KI lesen zu lassen und OCR-Text zu erstellen. Der Vorgang wird je nach Leistung pro Seite einige Minuten dauern. Anschließend kannst du mit Klicken auf Save Content den neuen OCR-Inhalt zum Dokument hinzufügen und den ursprünglichen damit ersetzen.
Möchtest du einmal eine Änderung rückgängig machen, die durch paperless-gpt durchgeführt wurde, kannst du das im Reiter History tun.
Bei Fragen oder Anregungen freue ich mich natürlich über eure Kommentare.
Wenn dir der Beitrag geholfen hat, freue ich mich über deine Unterstützung über die Schaltfläche links unten – vielen Dank!
Über mich
Ich bin Janis (aka. EurenikZ), 27 Jahre alt und komme aus der Nähe von Frankfurt am Main. Ich habe eine abgeschlossene IHK-Ausbildung zum Fachinformatiker für Systemintegration und arbeite als Junior IT-Administrator in einem IT-Systemhaus. Neben meinem IT-Blog beschäftige ich mich viel mit diversen IT-Themen und meinen Webseiten sowie Telegram Bots und biete IT-Dienstleistungen an.




